About APE-Bench I
Formal mathematics is approaching a critical scalability limit. As libraries like Mathlib4 grow rapidly in size and complexity, traditional approaches to manual proof development are no longer sustainable. The future lies not just in automating individual theorem proving, but in building Automated Proof Engineering (APE) systems—intelligent infrastructure that can understand, manage, refactor, and evolve large-scale formal codebases much like modern software engineering systems, while ensuring mathematical correctness at every step.
This represents a fundamental shift from reactive proof search to proactive, AI-supported collaboration in mathematical formalization. Instead of merely solving isolated problems, APE systems must handle the full spectrum of real-world development challenges: dependency management, API evolution, coordinated refactoring, and continuous integration workflows adapted for mathematical rigor.
Realizing this vision requires more than algorithmic advances—it demands a robust, open research ecosystem. Fragmented tooling and isolated experiments slow progress across the field. What's needed is a unified foundation that enables reproducible research, community-driven development, and standardized evaluation practices. APE-Bench I represents our contribution toward building this essential infrastructure for the emerging APE research community.
APE-Bench I: From Vision to Implementation
APE-Bench I operationalizes this vision by introducing instruction-guided file-level editing tasks derived from real Mathlib4 development workflows. Moving beyond traditional isolated theorem-proving benchmarks, it evaluates AI systems on the practical proof engineering challenges that formal mathematics practitioners face daily: refactoring code, adding features, debugging errors, and maintaining consistency across evolving codebases.
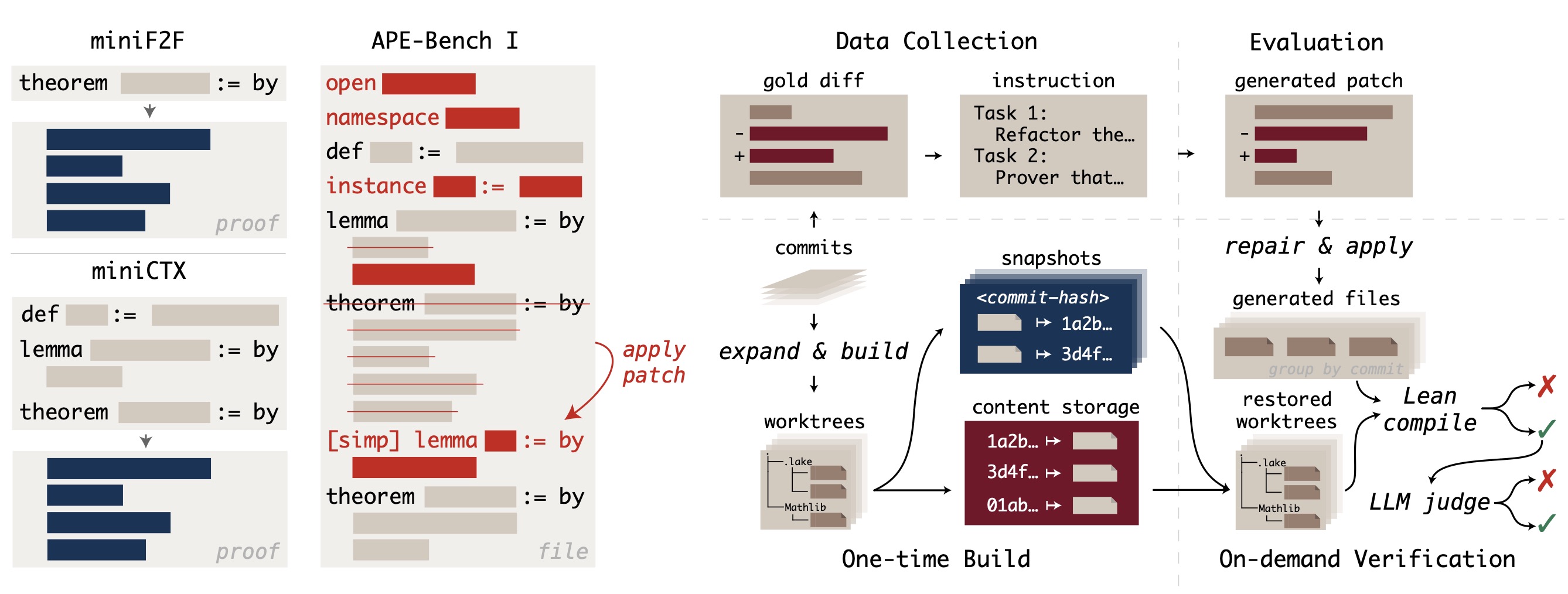
APE-Bench I: Benchmark structure and evaluation pipeline
Core Design Principles
APE-Bench I is built on four foundational goals that ensure its relevance and rigor:
- Realism: Extracted from actual Mathlib4 commits, preserving the structural integrity and complexity of real development practices
- Stratification: Multi-stage filtering pipeline removes trivial edits and categorizes tasks by function and difficulty to support diverse evaluation needs
- Scalable Syntax-Semantics Evaluation: Combines syntactic verification via Lean compiler with semantic judgement through LLM-as-a-judge systems
- Continual Evolvability: Fully automated construction pipelines enable updates that evolve with the underlying library
Positioning in the APE Research Landscape
APE-Bench I serves as the foundation for a staged progression toward comprehensive automated proof engineering capabilities:
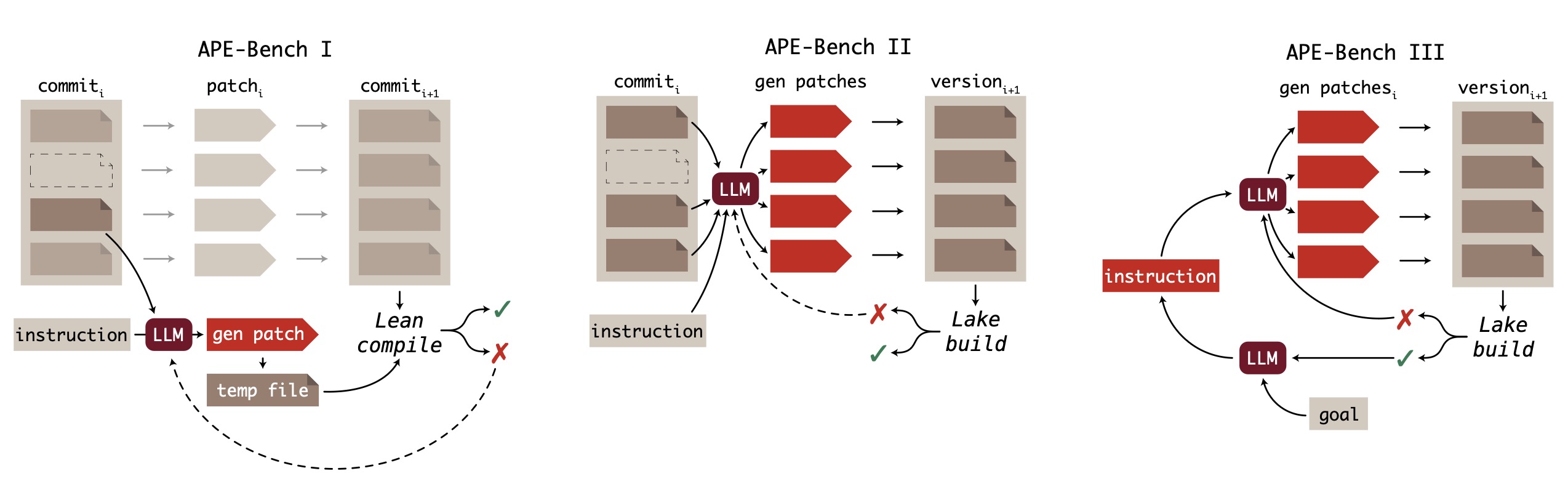
The APE-Bench series: A staged roadmap for automated proof engineering
- APE-Bench I (Current): Single-file instruction-guided edits with localized scope—establishing fundamental evaluation protocols
- APE-Bench II (Future): Multi-file coordination and project-level verification—scaling to realistic development workflows
- APE-Bench III (Vision): Autonomous workflows with planning, editing, and iterative repair—achieving human-level proof engineering capabilities
This progression mirrors the evolution from individual code editing to full software development lifecycle automation, but adapted for the unique constraints and requirements of formal mathematical reasoning.
Current Leaderboard
| Rank | Model | Samples | Easy Pass Rate (%) | Medium Pass Rate (%) | Hard Pass Rate (%) | Overall Pass Rate (%) |
|---|
Last updated: May 20 2025. Results are based on the pass@k metric with hybrid syntax-semantics evaluation.
Latest News
- May 2025: APE-Bench I selected as Track 1 of the ICML 2025 AI4Math Workshop Challenge, providing a platform for automated proof engineering evaluation
- May 2025: Dataset and evaluation infrastructure released, providing the research community with reproducible multi-version Lean evaluation capabilities
Current Activities
ICML 2025 Competition
APE-Bench I serves as Track 1 of the ICML 2025 AI4Math Workshop Challenge, providing researchers with a platform to evaluate their automated proof engineering systems.
Key Information
- Final Evaluation: July 7, 2025
- Submission Portal: Codabench
- Submission Limits: Maximum 5 submissions per day, 100 total for the entire competition period
Evaluation Tracks
- Public Leaderboard: Evaluated on the canonical test split from our paper and displayed on this website. Results are updated weekly based on community submissions, providing transparent performance tracking.
- Private Leaderboard: Uses a hidden portion of the test set with strengthened semantic judging to minimize overfitting risk. Final results will be revealed on July 7, 2025.
Independent Evaluation
Researchers can independently evaluate their systems using APE-Bench I infrastructure:
- Complete Pipeline: Access the full evaluation infrastructure via GitHub
- Dataset Access: Download benchmark data from HuggingFace
- Technical Documentation: Detailed methodology in our arXiv paper
Ongoing Development & Community
APE-Bench I aims to serve as a foundation for building comprehensive automated proof engineering infrastructure. Our development extends beyond evaluation to create agent frameworks and community tools that support the entire APE research lifecycle.
Agent Framework Development
We are building APE-Bench I into a complete agent development platform through these focused phases:
Phase 1: Error-Driven Repair
- Compilation Error Resolution: Agents that interpret Lean compiler feedback and generate targeted fixes
- Iterative Refinement: Multi-round editing workflows with feedback loops and incremental improvement
- Key Deliverables: Error interpretation modules, iterative repair algorithms, baseline agent implementations
Phase 2: Context-Aware Systems
- Mathlib Integration: Information retrieval systems for relevant theorems, definitions, and proof patterns
- Context-Guided Generation: Code generation informed by retrieved mathematical context and library conventions
- Key Deliverables: Mathlib search APIs, context integration frameworks, retrieval-augmented agents
Phase 3: Integrated Workflows
- Tool Standardization: Unified APIs for compilation, retrieval, and verification as callable agent tools
- Framework Adaptation: Integration with mainstream agent architectures (agentless, allhands, etc.)
- Key Deliverables: Standardized tool interfaces, framework adapters, comparative evaluation protocols
Infrastructure Enhancement
Continuous improvement of our evaluation infrastructure to support advanced agent development:
Eleanstic Servicification
- Service Architecture: Transform from pipeline component to on-demand verification service with request queues
- API Development: RESTful interfaces supporting real-time compilation checking and batch processing
- Scalability: Containerized deployment and cloud infrastructure for high-throughput agent development
Semantic Evaluation Improvement
- Accuracy Enhancement: More robust semantic evaluation with reduced false positives and improved reliability
- Validation Framework: Human-verified ground truth datasets for measuring evaluation system accuracy
- Specialized Models: Judge models trained specifically for proof engineering task evaluation
Engineering Excellence
- Development Infrastructure: Comprehensive CI/CD pipelines, automated testing, and deployment systems
- Documentation Standards: Unified API references, contribution guidelines, and technical documentation
- Quality Assurance: Code standards, performance monitoring, and maintainability improvements
How to Contribute
Join our effort to build unified, reusable APE research infrastructure. We emphasize collaborative development within a well-maintained codebase to maximize research impact and prevent fragmented efforts.
Contribution Process
- Issue Discussion: Report bugs and technical challenges via GitHub Issues
- Feature Planning: Propose new features and research directions through GitHub Discussions
- Development: Fork repository, implement in dedicated branches, submit PRs with comprehensive documentation
Impact & Recognition
- Academic Publication: We actively encourage contributors to publish their work—technical reports, research papers, and novel approaches that advance the APE field
- Research Collaboration: Connect with core team members and fellow contributors for joint research projects
- Field Development: Help establish evaluation practices and methodologies for the emerging APE research area
- Community Influence: Shape the direction of APE research through contributions that become part of the shared infrastructure